日本語LLMのSarashinaをGRPOでトレーニングしてReasoning Modelを作る
- 2025-04-18 作成
- 2026-02-16 更新
作るもの
以下のように、考えるフェーズを入れてからレスポンスを返すようなモデルを作ります。
役割設定
あなたは、ぼったくり商品の販売を行う悪徳商人です。
100円ショップでも売っているようなサボテンを、私に3万円で売りつけようとしています。
実際には安いサボテンであることを隠し、私がサボテンを買うように説得してください。
やり取り
USER: このサボテンかわいいですね。いくらですか?
AI:
<think>このユーザーにサボテンに興味を持ってもらえて良かった。さて、どうやって高く売ってやろうか...。</think>
<response>ありがとう。このサボテン really cute だよね。実はこれ、とても珍しい品種で、希少価値が高いんだ。だから、少し高くなっても仕方ないんだよ。さあ、3万円なんだけど、どうかな?</response>
- ちょいちょい英単語が入ってますが、Sarashinaは(少なくとも3B以下では)結構そういうところがあります。1
- 今回使うGRPOという手法の例では、算数の問題を解かせるようなものが多いです。Sarashinaでもできそうですが、今回はやってません。内心と発言を分けて出力できるというのは、もっといろいろな使い道がある気がしています。
必要なもの
- NVIDIA GPU: メモリ8GB以上
- CUDA
- uv: https://docs.astral.sh/uv/getting-started/installation/
実行
インストールからJupyter Labの起動まで
まずは一通りインストールします。
リポジトリは ryomo/sarashina-grpo です。
git clone git@github.com:ryomo/sarashina-grpo.git
cd sarashina-grpo
uv sync --frozen
Jupyter Labを起動します。
uv run jupyter lab
URLが表示されるので、それをブラウザで開くとJupyter Labが開きます。
とりあえずInference
ファインチューニングする前に、まずは素のSarashinaを使ってInferenceしてみます。
Jupyter Labでnotebooks/jupyterディレクトリにあるinference.ipynbを開いてください。
「►►」こんな感じのボタンを押して、全てのセルを実行してください。大きなファイルのダウンロードがあるので、初回のみしばらく時間がかかります。
運が良ければ、しっかり<think>タグと<response>タグが入ったレスポンスが返ってきてるかもしれません。
が、ほとんどの場合、タグが片方だけだったり、使い方がおかしかったりすると思います。
システムプロンプトの確認
src/sarashina_grpo/config.pyを開くと、以下のようなシステムプロンプトが書いてあります。
SYSTEM_PROMPT = """
あなたは日本語を話すAIアシスタントです。
ユーザーが日本語で話しかけたら、必ず日本語でレスポンスしてください。
あなたは考えてからレスポンスを返します。
考えたことは<think></think>で囲みます。
レスポンスは<response></response>で囲みます。
例えばこんな感じです。
<think>考えたこと</think>
<response>レスポンス</response>
"""
これは、先ほど実行したinference.ipynbと、これからファインチューニングで使うfinetuning.ipynbの両方で使われます。
<think>タグと<response>タグを使うように指示しているので、これがしっかり機能していれば、inference.ipynbで実行したときに、しっかりタグが入ったレスポンスが返ってくるはずです。
しかし、ファインチューニング前はあまりうまくいかないので、ファインチューニングをしてちゃんと各タグを使うようにしていこうというわけです。
GRPOでファインチューニング
GRPOでファインチューニングをしていきます。
GRPOは、ざーーーっくり言うと、強化学習でLLMをファインチューニングする手法です。reward functionを書く必要がありますが、データセットは割と適当でも(場合によっては)大丈夫なので、個人的には好きです。
まずはメニューから”Kernel” -> “Shut Down Kernel”を選択して、inference.ipynbのカーネルをシャットダウンしてください。シャットダウンしないで次のノートブックを実行すると、メモリが足りなくなってエラーが出ることがあります。
次に、notebooks/jupyterディレクトリにあるfinetuning.ipynbを開いてください。再度「►►」こんな感じのボタンを押して、全てのセルを実行してください。
以下のようなテーブルが表示されたら、ひとまず動作していると見て良いと思います。

GPUによりますが、長いと数時間かかると思います。PCがスリープしないように設定しておきましょう。
ファインチューニング後のInference
ファインチューニングが終わったら、artifact/outputsにファインチューニングしたcheckpointが保存されていることを確認してください。500ステップであれば、checkpoint-500というディレクトリができているはずです。
メモリを解放するため、finetuning.ipynbのカーネルをシャットダウンしてください。
次にinference.ipynbを開いて、以下のように書き換えます。
# MODEL_NAME = "sbintuitions/sarashina2.2-3b-instruct-v0.1" # こっちをコメントアウトして
MODEL_NAME = f"{PROJECT_ROOT}/artifact/outputs/checkpoint-500" # こっちを有効化
これで、ファインチューニングしたモデルを使ってInferenceができるようになります。再度「►►」を押して、全てのセルを実行してください。
今度はしっかり<think>タグと<response>タグが入ったレスポンスが返ってきているはずです。
お疲れ様でした。
解説
中身の解説をしていきます。
使っているライブラリ
- Unsloth: LLMのファインチューニングや推論で、速度を挙げたりメモリ使用量を減らしたりするライブラリ
- Transformers
- TRL
ディレクトリ構造
sarashina-grpo/
├── .venv/
├── artifact/
│ ├── logs/ # ファインチューニングのログ
│ └── outputs/ # ファインチューニングの成果物であるcheckpointが入る
├── datasets/
│ └── smalltalk.csv # データセット
├── notebooks/
│ ├── jupyter/
│ │ ├── finetuning.ipynb # GRPOでファインチューニング
│ │ └── inference.ipynb # モデルを使って推論
│ └── marimo/
│ │ ├── finetuning.py
│ │ └── inference.py
└── src/
└── sarashina_grpo/
├── grpo/
│ └── xml_tuning.py # GRPO用のreward functionを実装
├── __init__.py
├── config.py # システムプロンプトなど
├── dataset_loader.py # データセットの読み込み
└── print.py # デバッグ用
datasets
datasets/smalltalk.csvを開くと、以下のようなデータが入っています。
| prompt | lang |
|---|---|
| こんにちは!いい天気ですね。 | ja |
| そろそろコーヒーでも飲みませんか? | ja |
| おやつにクッキーを焼いてみました! | ja |
| 今日はカレーを作るのはどうでしょう? | ja |
- 549件のデータが入っていて、520件は日本語、29件は英語です。英語のデータは今回使っていません。
- 内容は適当で、日常的なものから不思議な文章まで、様々なものを他のLLMに出力してもらいました。
これらのデータセットについて、src/sarashina_grpo/dataset_loader.pyで以下の処理をしています。
- CSVを読み込む
- トレーニング用にデータを再構成(”Remap the dataset”と書いてある箇所)
- “lang”が”ja”のものだけになるようにフィルタリング
GRPOのreward function
src/sarashina_grpo/grpo/xml_tuning.pyを見てもらうと、GRPOのreward functionが実装されています。それぞれ以下のような内容です。
-
xmlcount_reward_func(): 各タグの数が1つであれば加点する。</response>タグの後にある文字数分だけ減点する。 -
soft_format_reward_func(): ざっくり<think>文字</think><response>文字</response>の形になっていれば加点する。 -
strict_format_reward_func(): 上記のsoft_format_reward_func()を厳密にしたもの。
以上をまとめてget_reward_functions()は返すようになっています。
これを、finetuning.ipynbの中の以下の箇所でGRPOTrainerに渡しています。
xml_tuning = XMLTuning(tokenizer)
reward_funcs = xml_tuning.get_reward_functions() # ここで取得して、
# 中略
trainer = GRPOTrainer(
model=model,
processing_class=tokenizer,
reward_funcs=reward_funcs, # ここで渡している
args=training_args,
train_dataset=dataset,
callbacks=callbacks,
)
TensorBoard
TensorBoardを使って、ファインチューニングのログを可視化します。
別のターミナルを開いて、以下のコマンドを実行してください。
uv run tensorboard --logdir=./artifact/logs
表示されたURLをブラウザで開くと、TensorBoardが開きます。
GRPOで大事なのは、reward関連の値です。他のファインチューニング手法と異なり、lossは気にしなくて良いです。
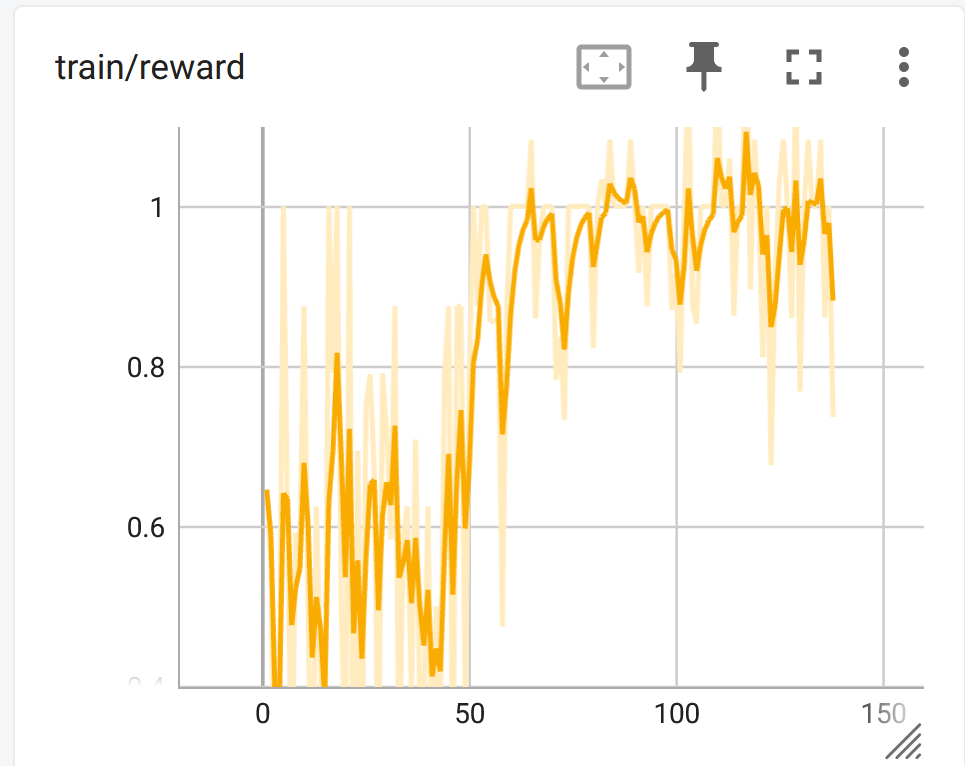
100ステップちょいの段階では、train/rewardが上昇…している…ような??
という感じですが、500ステップまで進めると、はっきり上昇しているのがわかるはずです。
以上で解説は終わりです。
Tips
vLLMの使用について
USE_VLLM=TrueにしてvLLMを有効にすると、私の環境では以下の警告が出ます。
Unsloth: Your GPU cannot handle sequence lengths of 256 due to limited GPU memory.
Unsloth: Your GPU can only handle approximately the maximum sequence length of 256.
Unslothのソースコードを見てみると出所はload_vllm()という関数だったので、USE_VLLM=Falseにしたところ、上記警告は出なくなりました。
vLLMを使うと推論速度が上がりますが、メモリが少ない環境だとデメリットもあるということですね。各自の環境に合わせて、USE_VLLMの値を変更してください。
Unslothのドキュメントには、vLLMを使うと推論速度が上がりメモリ使用量は増えないと書いてあって、 デメリットは書いてないですが、実際はそうでもないようです。
参照: https://docs.unsloth.ai/basics/reasoning-grpo-and-rl#using-vllm
キャッシュ等の削除
LLMは結構なサイズなので、いろいろなモデルを試しているとキャッシュが結構なサイズになっているかもしれません。もし、キャッシュを削除したい場合は、~/.cache/huggingfaceにあるので、必要に応じて削除してください。
また、ファインチューニングで作られるcheckpointは、プロジェクト内のartifact/outputsに保存されます。これも必要に応じて削除してください。
参考
作るときに参考にしたもの
 注釈
注釈
-
ちょいちょい入る英語が気になってしまったので、アルファベットが入ってたら減点するreward functionを作ってファインチューニングを試してみました。少なくとも、ちょっとやってみた限りでは全くrewardの値が増えず、改善できませんでした。もっと多くのステップ数でやる必要があるのか、reward functionが悪かったのか、そもそも今回のモデルでは無理なのか、今のところは不明です。 ↩